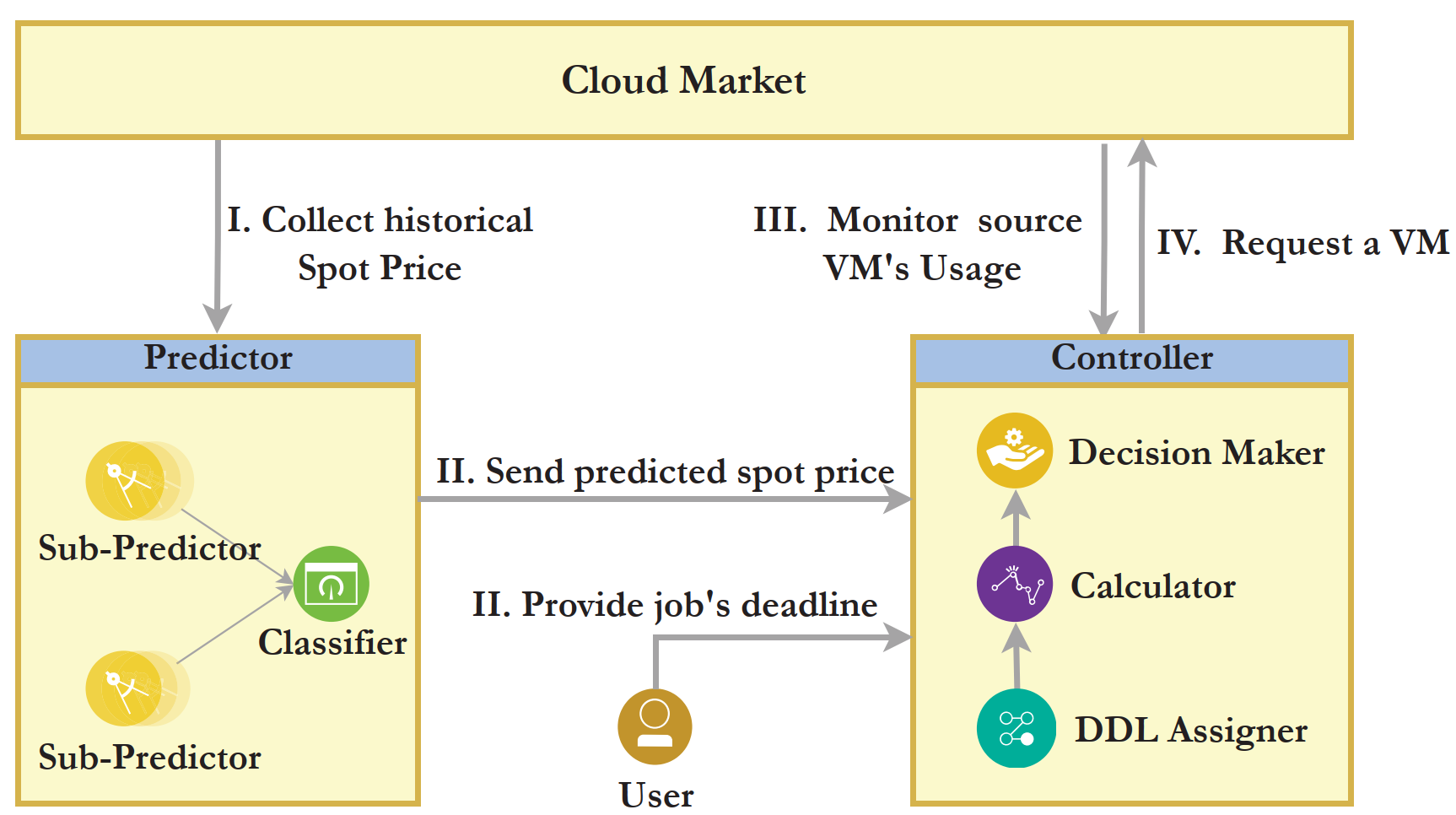
 FarSpot: Public clouds offer various pricing schemes to satisfy different user requirements (e.g., on-demand, reservation, spot). Among them, spot instances offer much cheaper resources compared to on-demand instances, with the risk of unexpected instance failures when out-of-bid events occur. To take advantage of the low prices of spot instances while providing reliable execution for applications, in this project, we propose an ensemble-based predictor to accurately forecast spot price variations in near future and an instance migration strategy that can dynamically and efficiently migrate tasks from instances that are going to fail. This project offers a practical solution for long-running tasks to execute on spot instances with a low cost.
FarSpot: Public clouds offer various pricing schemes to satisfy different user requirements (e.g., on-demand, reservation, spot). Among them, spot instances offer much cheaper resources compared to on-demand instances, with the risk of unexpected instance failures when out-of-bid events occur. To take advantage of the low prices of spot instances while providing reliable execution for applications, in this project, we propose an ensemble-based predictor to accurately forecast spot price variations in near future and an instance migration strategy that can dynamically and efficiently migrate tasks from instances that are going to fail. This project offers a practical solution for long-running tasks to execute on spot instances with a low cost.
Results: SC'15 [pdf], TCC 2016 [pdf], TPDS 2022 [pdf]
|
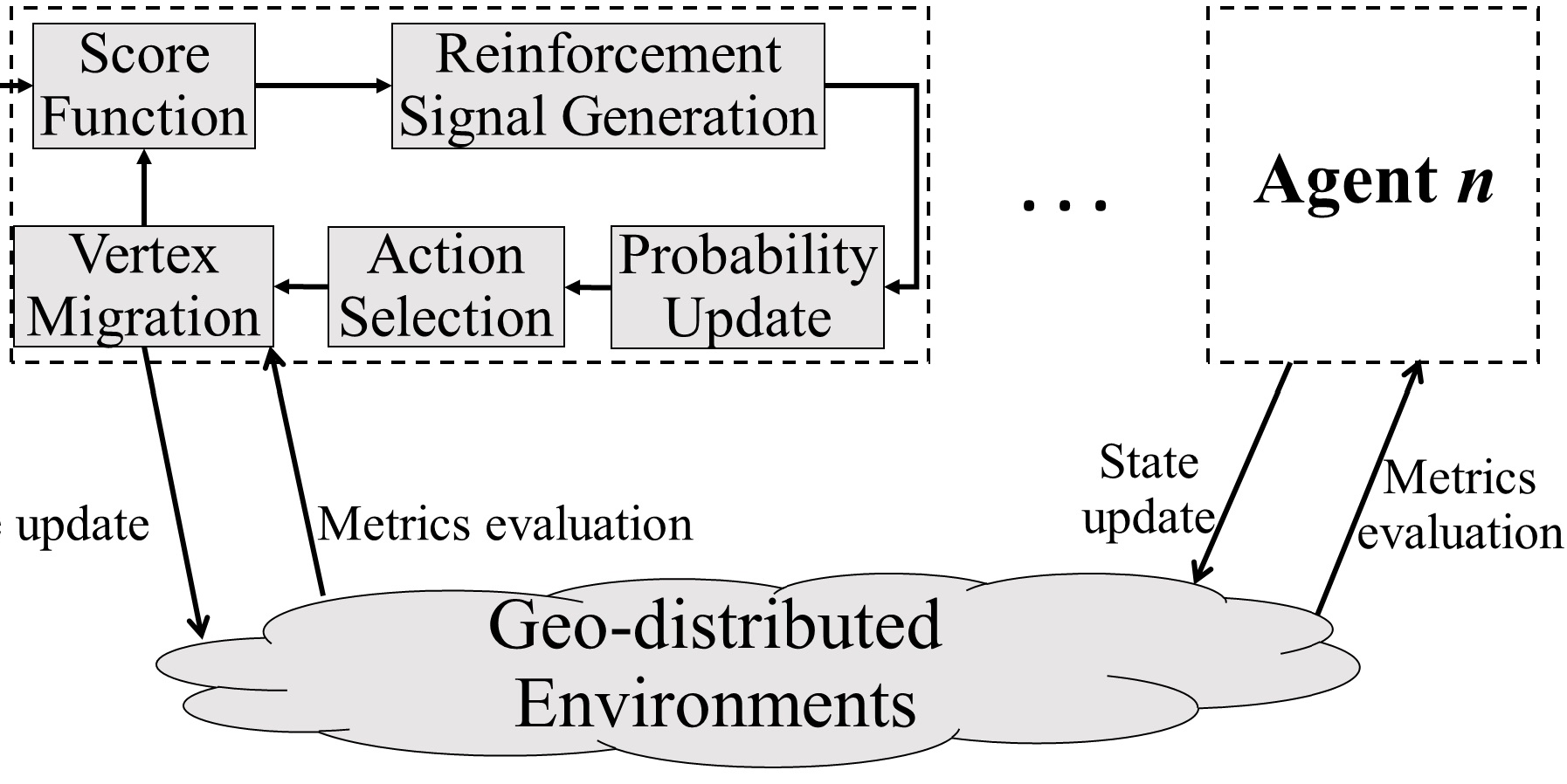 Adaptive Graph Partitioning: Graph partitioning is important to the performance of distributed graph processing. However, when dealing with large graphs, there is a trade-off between partitioning effectiveness and efficiency. This problem further complicates for dynamic graphs with different changing frequencies. In this project, we innovatively proposed to adopt multi-agent reinforcement learning to address the graph partitioning problem. With a
sampling-based technique to adaptively decide the number of agents participating in the training, we are able to adaptively achieve good balance between graph partitioning time and quality.
Adaptive Graph Partitioning: Graph partitioning is important to the performance of distributed graph processing. However, when dealing with large graphs, there is a trade-off between partitioning effectiveness and efficiency. This problem further complicates for dynamic graphs with different changing frequencies. In this project, we innovatively proposed to adopt multi-agent reinforcement learning to address the graph partitioning problem. With a
sampling-based technique to adaptively decide the number of agents participating in the training, we are able to adaptively achieve good balance between graph partitioning time and quality.
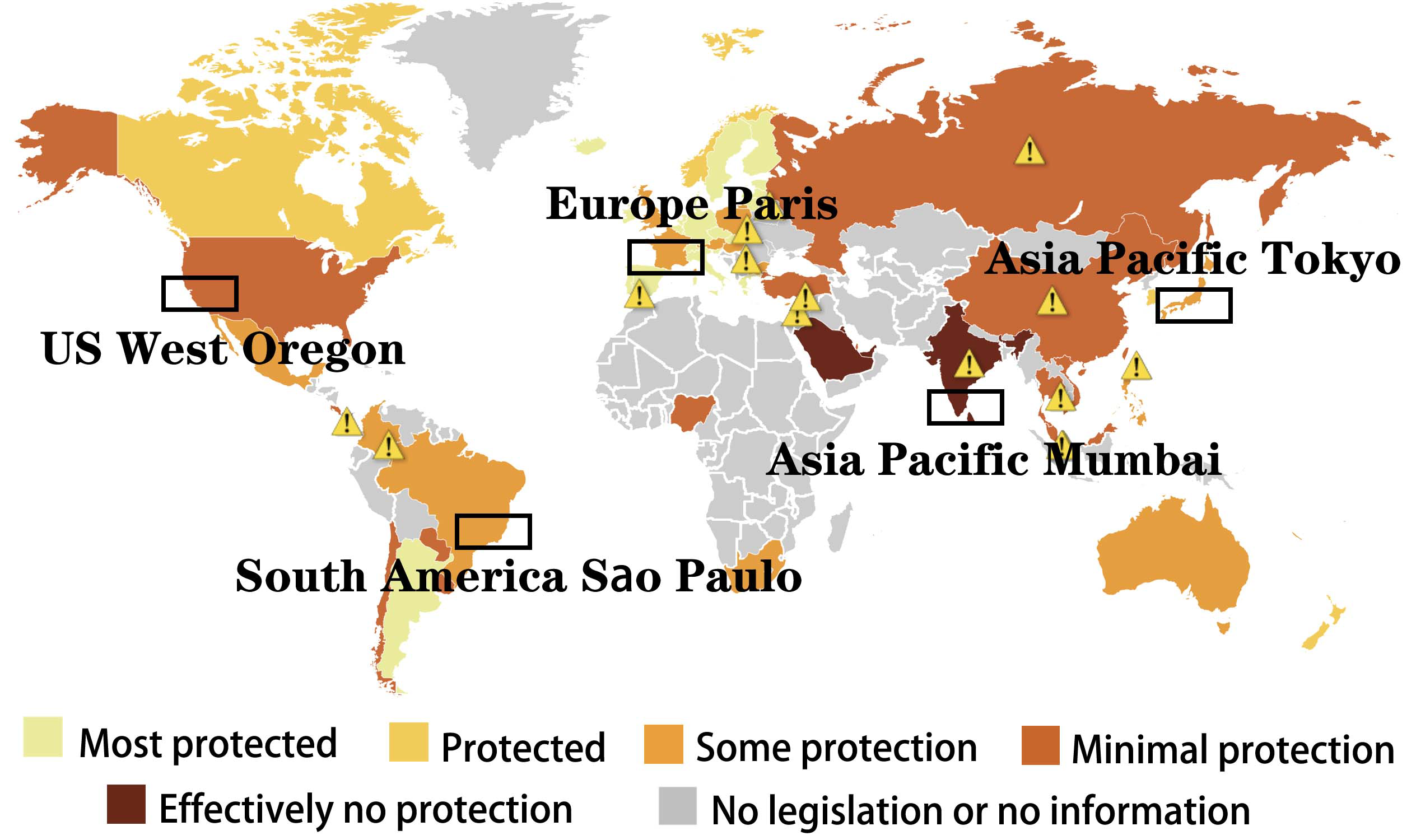 PGPregel: In this project, we propose an end-to-end system for privacy-preserving graph processing in geo-distributed data centers. PGPregel adopts Differential Privacy (DP) to ensure privacy requirements casted by GDPR, and incorporates sampling and combiners techniques to make DP practical. To the best of our knowledge, this is the first of its kind to consider system latency, utility and privacy at the same time for geo-distributed graph processing. Currently, we are working on how to decide the hyperparameters of PGPregel (e.g., sampling rate, number of combiners) in an automatic and adaptive way.
PGPregel: In this project, we propose an end-to-end system for privacy-preserving graph processing in geo-distributed data centers. PGPregel adopts Differential Privacy (DP) to ensure privacy requirements casted by GDPR, and incorporates sampling and combiners techniques to make DP practical. To the best of our knowledge, this is the first of its kind to consider system latency, utility and privacy at the same time for geo-distributed graph processing. Currently, we are working on how to decide the hyperparameters of PGPregel (e.g., sampling rate, number of combiners) in an automatic and adaptive way.
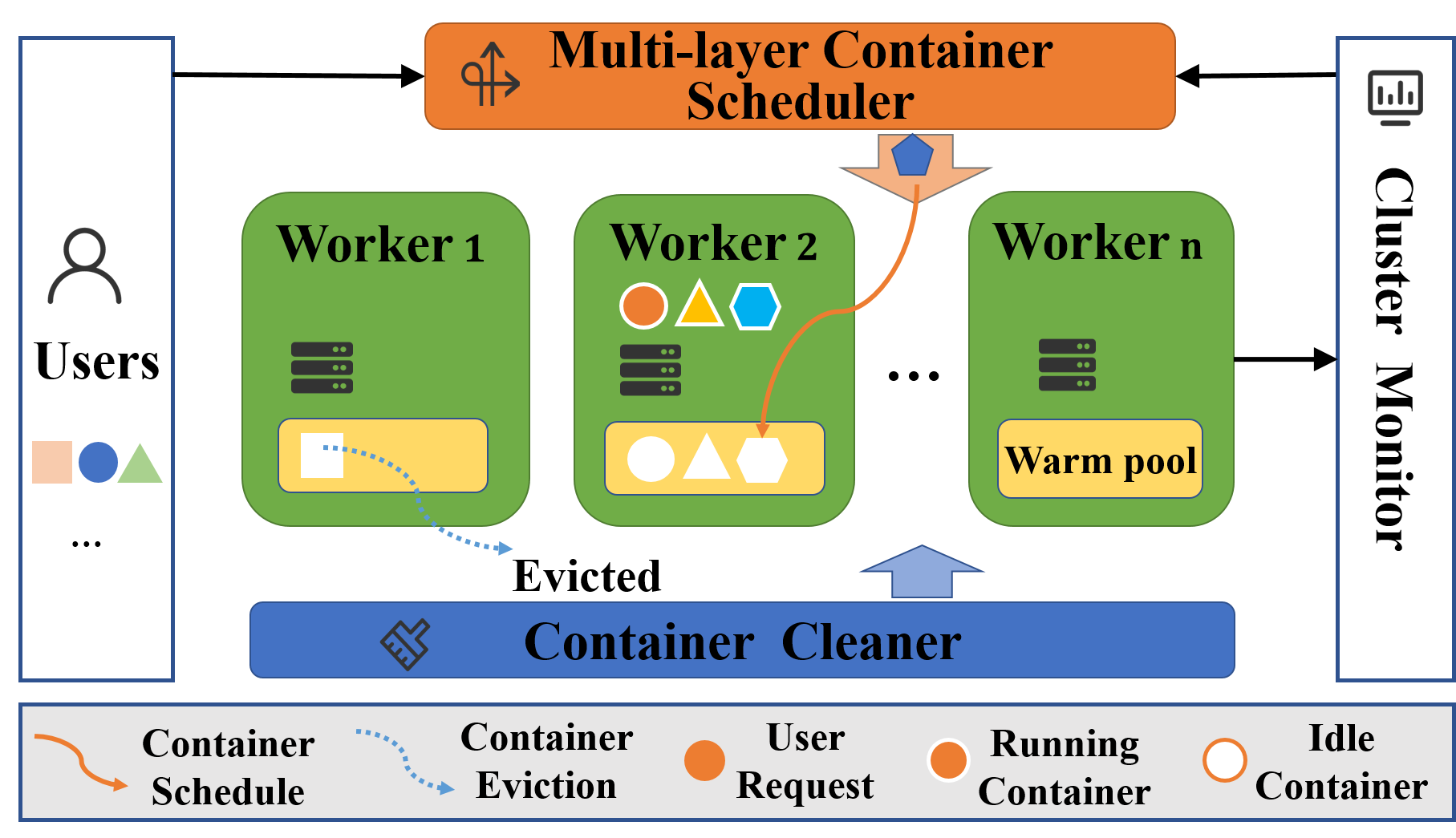 Multi-Layer Container Reuse (MLCR): In serverless computing, cold-start latency of containers is a major challenge to improving the performance of serverless applications. Existing techniques proposed to reuse warm containers in the platform to mitigate cold-start latency of functions to improve overall application performance. However, the utilizations of warm containers in existing systems are still low due to the complexity of real serverless workloads. In this project, we propose to reuse containers at multiple layers to greatly improve warm container utilization. Furthermore, we design a public benchmark named FStartBench for evaluating the effectiveness of different function warm start strategies.
Multi-Layer Container Reuse (MLCR): In serverless computing, cold-start latency of containers is a major challenge to improving the performance of serverless applications. Existing techniques proposed to reuse warm containers in the platform to mitigate cold-start latency of functions to improve overall application performance. However, the utilizations of warm containers in existing systems are still low due to the complexity of real serverless workloads. In this project, we propose to reuse containers at multiple layers to greatly improve warm container utilization. Furthermore, we design a public benchmark named FStartBench for evaluating the effectiveness of different function warm start strategies.
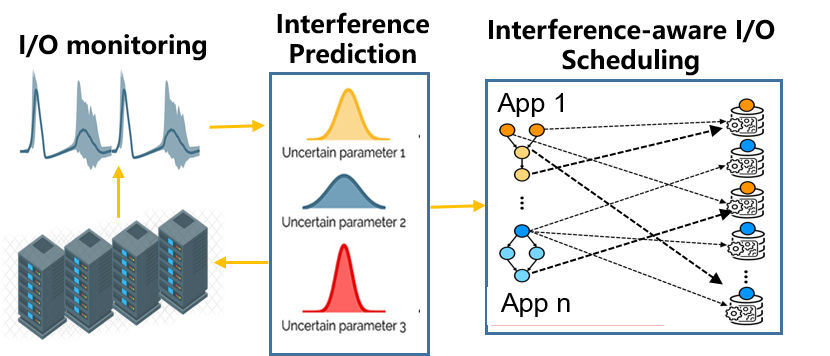 Interference-aware I/O Scheduling: In HPC systems, concurrent I/Os lead to resource contention and unavoidable I/O interferences. The degree of performance degradation caused by interferences is hard to predict due to the different I/O patterns, hardware features and I/O scheduling policies. To improve system performance, we have strived to design novel I/O scheduling mechanisms to minimize interferences, through analyzing workload I/O patterns and the read/write interference features of underlying storage medium. We are collaborating with National Supercomputing Centre in Shenzhen to make our strategies practical and applicable in real systems.
Interference-aware I/O Scheduling: In HPC systems, concurrent I/Os lead to resource contention and unavoidable I/O interferences. The degree of performance degradation caused by interferences is hard to predict due to the different I/O patterns, hardware features and I/O scheduling policies. To improve system performance, we have strived to design novel I/O scheduling mechanisms to minimize interferences, through analyzing workload I/O patterns and the read/write interference features of underlying storage medium. We are collaborating with National Supercomputing Centre in Shenzhen to make our strategies practical and applicable in real systems.